Redis (Remote Dictionary Server ) 远程字典服务,是当下最热门的 NoSQL 技术之一,也被人们称为结构化数据库。
Redis 是一个开源的使用 ANSI C 语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的 APl。
和 Memcached 类似,它支持存储的 value 类型相对更多,包括:
- string(字符串)
- list(链表)
- set(集合)
- zset(sorted set 有序集合)
- hash(哈希类型)
与 memcached 一样,为了保证效率,数据都是缓存在内存中。
区别的是 redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了 master-slave (主从) 同步。
简介
Redis 是完全开源免费的,遵守 BSD 协议,是一个高性能的 key-value 数据库,它可以用作数据库、缓存和消息中间件。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
- Redis 不仅仅支持简单的 key-value 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。
- Redis 支持数据的备份,即 master-slave 模式的数据备份。
优势
- 性能极高
Redis 能读的速度是 110000 次/s,写的速度是 81000 次/s 。
- 丰富的数据类型
Redis 支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子
Redis 的所有操作都是原子性的,同时 Redis 还支持对几个操作全并后的原子性执行。
- 丰富的特性
Redis 还支持 publish/subscribe, 通知, key 过期等等特性。
Redis 与其他 Key-value 存储的区别
- Redis 运行在内存中但是可以 持久化到磁盘,重启的时候可以再次加载进行使用。
- Redis 不仅仅支持简单的 Key-Value 类型的数据,同时还提供 List,Set,Sorted set,hash 等数据结构的存储。
- Redis 还支持数据的备份,即 Master-Slave 主从模式的数据备份。
Redis 和 MongoDB 的区别
更多可见:NoSQL,浅谈redis与mongoDB的区别 - 知乎
- 性能方面,二者都很高,总体而言,TPS 方面 Redis 要大于 MongoDB;
- 可操作性上,MongoDB 支持丰富的数据表达、索引,最类似于关系数据库,支持 丰富的查询语言,操作比 Redis 更为便利;
- 内存及存储方面,MongoDB 适合 大数据量存储,依赖操作系统虚拟做内存管理,采用镜像文件存储,内存占有率比较高,Redis 2.0 后增加 虚拟内存特性,突破物理内存限制,数据可以设置时效性;
- 对于数据持久化和数据恢复,MongoDB 1.8 后,采用 binlog 方式(同 MySQL)支持持久化,增加了可靠性,而 Redis 依赖快照进行持久化、AOF 增强可靠性,但是增强可靠性的同时,也会影响访问性能;
- 在数据一致性上,MongoDB 不支持事务,靠客户端自身保证,而 Redis 支持事务,能保证事务中的操作按顺序执行;
- 数据分析上,MongoDB 内置 数据分析功能(mapreduce),而 Redis 不支持数据分析;
- 应用场景不同,MongoDB 适合海量数据,侧重于访问效率的提升,而 Redis 适合于较小数据量,侧重于性能。
数据类型
Redis 支持五种数据类型:
string(字符串)hash(哈希)list(列表)set(集合)zset(sorted set:有序集合)
String
最基本的类型,一个 key 对应一个 value。string 类型是二进制安全的,即 redis 的 string 可以包含任何数据。比如 jpg 图片或者序列化的对象 。
一个键最大能存储 512MB。
1 | redis 127.0.0.1:6379> set name "sukiu.top" |
Hash
Redis hash 是一个键值 (key=>value) 对集合。Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
每个
hash可以存储 232 - 1 键值对(40 多亿)。
1 | redis 127.0.0.1:6379> hmset user:1 username sukiu.top password sukiu.top points 200 |
List
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储 40 多亿)。
1 | 127.0.0.1:6379> lpush test redis |
Set
Redis 的 Set 是 string 类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储 40 多亿个成员)。
1 | 127.0.0.1:6379> sadd t1 redis |
Zset
和 set 不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
zset 的成员是唯一的,但分数 (score) 却可以重复。
1 | 127.0.0.1:6379> zadd t2 0 redis |
Redis 有序集合(sorted set)_w3cschool
高级
持久化
Redis 是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。
Redis 支持两种方式的持久化:RDB 快照和 AOF。
RDB
RDB 快照用官方的话来说:RDB 持久化方案是按照指定时间间隔对你的数据集生成的时间点快照(point-to-time snapshot)。
它以紧缩的二进制文件保存 Redis 数据库某一时刻所有数据对象的内存快照,可用于 Redis 的数据备份、转移与恢复。
到目前为止,仍是官方的默认支持方案。
原理: Redis 会单独创建 ( fork ) 一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。
整个过程中,主进程是不进行任何 I0 操作的,确保了极高的性能。
优点:
- 适合大规模的数据恢复
- 对数据的完整性要不高
缺点:
- 需要一定的时间间隔进程操作,如果 redis 意外宕机了,这个最后一次修改数据就没有的了
- fork 进程的时候,会占用一定的内容空间
AOF
AOF(Append Only File),它是 Redis 的完全持久化策略。
原理: 以日志的形式来记录每个写操作,将 Redis 执行过的所有指令记录下来 (读操作不记录) ,只许追加文件但不可以改写文件,,redis 启动之初会读取该文件重新构建数据。
换言之,redis 重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
AOF 持久化默认是关闭的,修改 redis.conf 以下信息并重启,即可开启 AOF 持久化功能。
1 | # no-关闭,yes-开启,默认no |
优点:
- 每一次修改都同步,文件的完整会更加好
- 每秒同步一次,可能会丢失一秒的数据
- 从不同步,效率最高
缺点:
- 相对于数据文件来说, aof 远远大于 rdb,修复的速度也比 rdb 慢
- Aof 运行效率也要比 rdb 慢,所以我们 redis 默认的配置就是 rdb 持久化
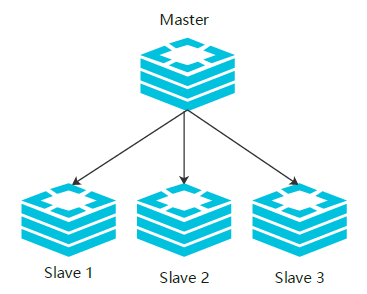
主从复制
主从复制:是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。
- 前者称为主节点 (master/leader)
- 后者称为从节点 (slavel/follower)
- 数据的复制是单向的,只能由主节点到从节点。Master 以写为主,Slave 以读为主。
默认情况下,每台 Redis 服务器都是主节点
一个主节点可以有多个从节点 (或没有从节点),但一个从节点只能有一个主节点
主从复制的作用主要包括:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写 Redis 数据时应用连接主节点,读 Redis 数据时应用连接从节点) ,分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高 Redis 服务器的并发量。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是 Redis 高可用的基础。
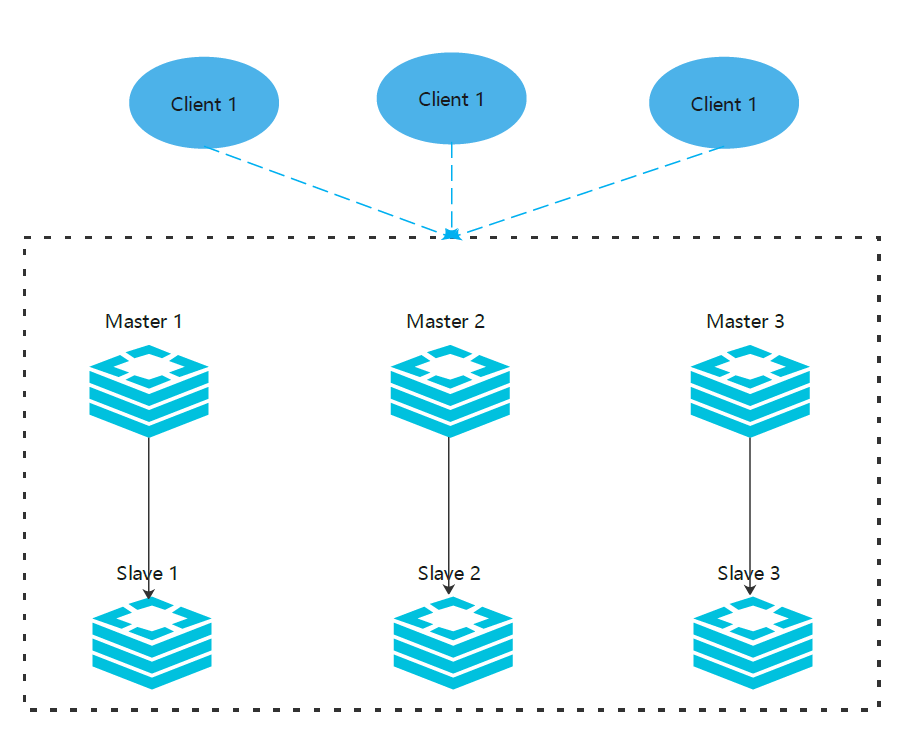
集群模式
主从
原理同上方的主从复制,系统的高可用都是通过部署多台机器实现的。
redis 为了避免单点故障,也需要部署多台机器。
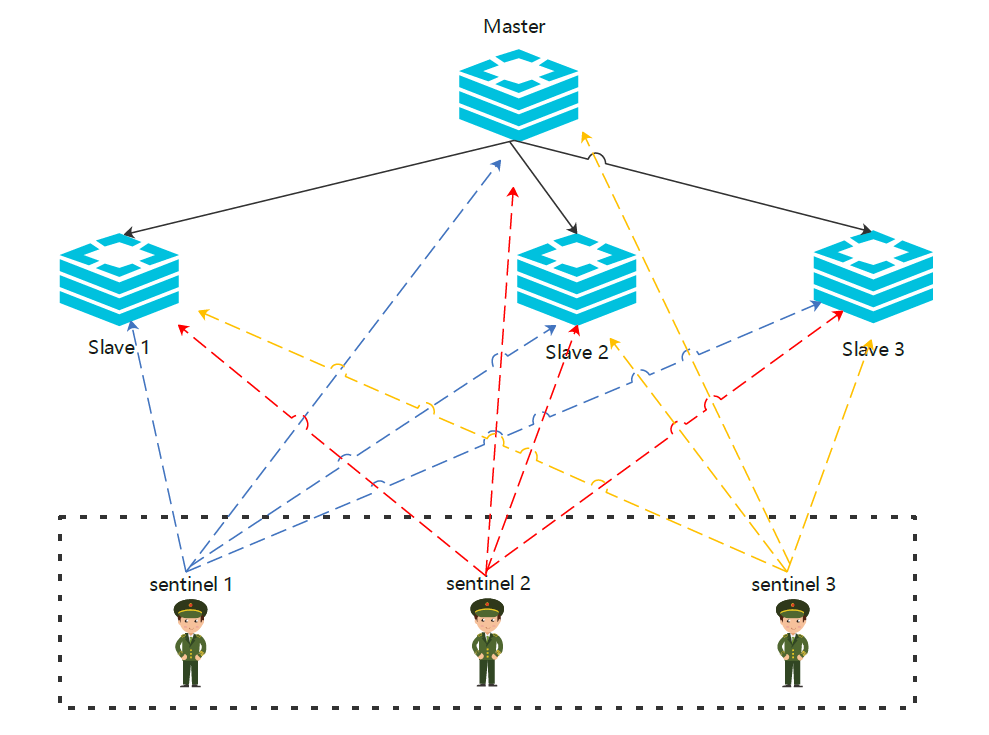
哨兵
主从模式下,当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。
实际生产中,优先考虑哨兵模式。这种模式下,master 宕机,哨兵会自动选举 master 并将其他的 slave 指向新的 master,即 自动选取老大的模式
集群
Redis 的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台 Redis 服务器都存储相同的数据,很浪费内存。
在 redis3.0 上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,对数据进行分片,也就是说每台 Redis 节点上存储不同的内容。