哈希表是一种使用哈希函数组织数据,以支持快速插入和搜索的数据结构。
散列
基本概念
散列:

碰撞:

散列函数:

除余法:

例子:

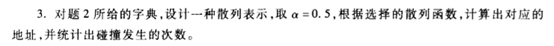
m=16*2=32
p=31
散列函数 h(key)=key%p
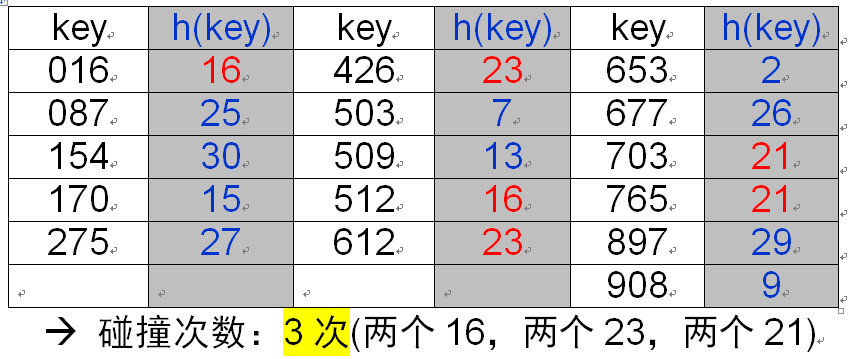
线性勘察法(开地址法处理碰撞)
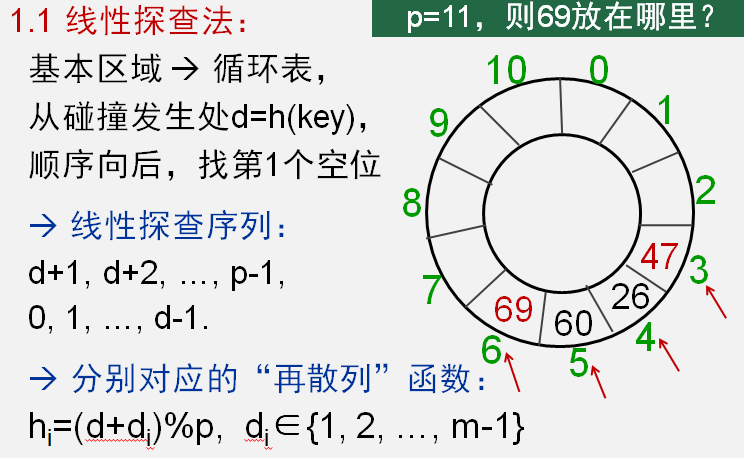
例子:

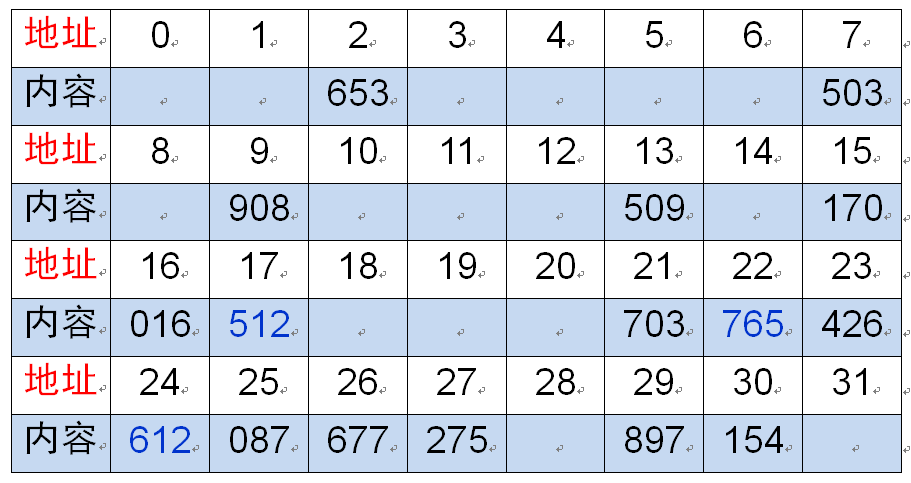
已知 n 个关键码具有相同的散列值 d,若采用线性探查法解决碰撞,则在散列这 n 个关键码的过程中,共将要发生n(n-1)/2 次碰撞
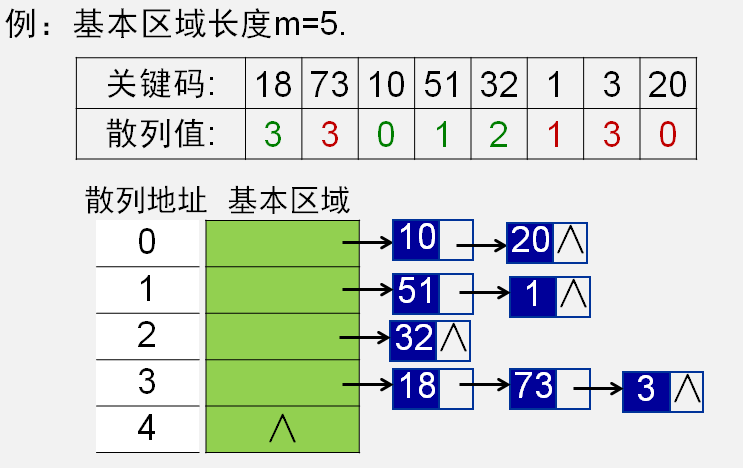
拉链法解决碰撞

例子:
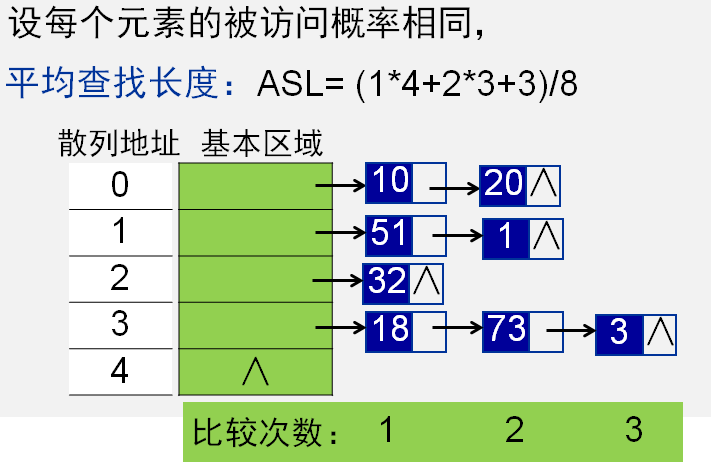
平均查找长度 ASL:
常见的三种哈希结构
参考:
当我们想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构。
- 数组
- set(集合)
- map(映射)
在 C++ 中,set 和 map 分别提供以下三种数据结构,其底层实现以及优劣如下表所示:
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O(logn) | O(logn) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1) |
- std::unordered_set 底层实现为哈希表
- std::set 和 std::multiset 的底层实现是红黑树
红黑树是一种平衡二叉搜索树,所以 key 值是有序的,但 key 不可以修改,改动 key 值会导致整棵树的错乱,所以只能删除和增加。
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key 有序 | key 不可重复 | key 不可修改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key 有序 | key 可重复 | key 不可修改 | O(logn) | O(logn) |
| std::unordered_map | 哈希表 | key 无序 | key 不可重复 | key 不可修改 | O(1) | O(1) |
- std::unordered_map 底层实现为哈希表
- std::map 和 std::multimap 的底层实现是红黑树
使用时:
- 解决哈希问题的时候,优先使用 unordered_set,因为它的查询和增删效率是最优的
- 如果需要集合是有序的,那么就用 set,如果要求不仅有序还要有重复数据的话,那么就用 multiset
map 中,对 key 是有限制,对 value 没有限制的,因为 key 的存储方式使用红黑树实现的。
java 里的 HashMap ,TreeMap 都是一样的原理。
虽然 std::set、std::multiset 的底层实现是红黑树,不是哈希表,但是 std::set、std::multiset 依然使用哈希函数来做映射,只不过底层的符号表使用了红黑树来存储数据,所以使用这些数据结构来解决映射问题的方法,我们依然称之为哈希法。 map 也是一样的道理。
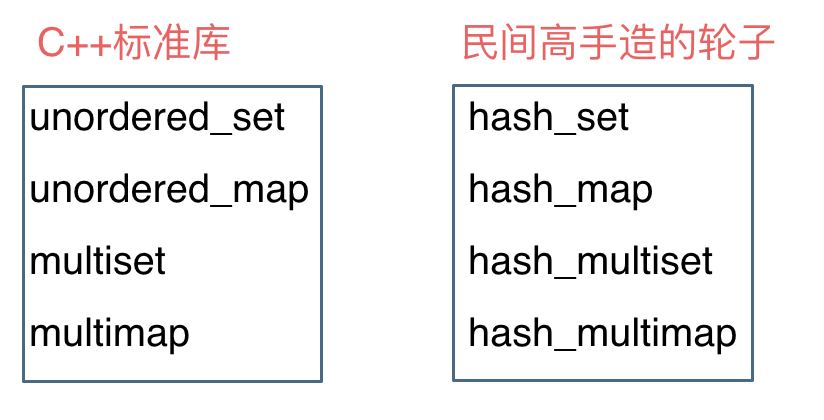
一些 C++ 的经典书籍上 例如 STL 源码剖析,说到了 hash_set hash_map,这个与 unordered_set,unordered_map 又有什么关系呢?
实际上功能都是一样一样的, 但是 unordered_set 在 C++11 的时候被引入标准库了,而 hash_set 并没有,所以建议还是使用 unordered_set 比较好,这就好比一个是官方认证的,hash_set,hash_map 是 C++11 标准之前民间高手自发造的轮子。